


(First published on Medium)
Introduction
The real estate sector is on the cusp of a transformative era, with Artificial Intelligence (AI) playing a pivotal role. From predictive analysis to personalized recommendations, AI is reshaping how we search for properties. In this blog we will look at how we can build an AI-powered real estate search engine using Qdrant, transforming property hunting with the power of vector similarity searches and LLMs.
Problem Statement
Traditional property search methods often rely on rigid keyword-based filters, leading to inefficient and frustrating user experiences. The challenge lies in developing a system that understands and responds to natural language queries, making property search as intuitive and efficient as possible.
Crafting the Solution
Dataset
Our journey begins with a comprehensive New York housing market dataset from Kaggle. This dataset serves as the foundation for our AI model, providing a rich source of property information. You can download this dataset from the following link: https://www.kaggle.com/datasets/nelgiriyewithana/new-york-housing-market
Initialization and Setup
This section imports necessary libraries and sets up our Streamlit UI. We initialize the Qdrant client, our embedding model, and the LLM for processing queries.
import streamlit as st
import pandas as pd
from qdrant_client import QdrantClient
from llama_index import ServiceContext, VectorStoreIndex, SQLDatabase
from llama_index.embeddings import FastEmbedEmbedding
from llama_index.llms import OpenAI
from sqlalchemy import create_engine
from pathlib import Path
To securely manage our application’s configuration, such as API keys and URLs, we utilize a .env file. This approach ensures sensitive information, like your OpenAI API key (OPENAI_API_KEY), Qdrant URL (QDRANT_URL), and Qdrant API key (QDRANT_API_KEY), is kept out of your main codebase, enhancing security and making it easier to update configurations without altering the source code. To implement this, first create a .env file in the root directory of your project and add the following lines:
OPENAI_API_KEY=your_openai_api_key_here
QDRANT_URL=your_qdrant_url_here
QDRANT_API_KEY=your_qdrant_api_key_here
Replace the placeholder text with your actual OpenAI API key, Qdrant URL, and Qdrant API key. The following code in the app.py file ensures that these environment variables are loaded:
import os
from dotenv import load_dotenv
load_dotenv()
Transforming Data into Text
The first step in our solution involves converting the rows of our housing dataset into a textual format. Each row, representing a property, is transformed into a structured text block. This text includes details like broker title, property type, price, number of bedrooms and bathrooms, square footage, and geographical coordinates.
def get_text_data(data):
return f"""
BROKERTITLE: {data['BROKERTITLE']}
TYPE: {data['TYPE']}
PRICE: {data['PRICE']}
BEDS: {data['BEDS']}
BATH: {data['BATH']}
PROPERTYSQFT: {data['PROPERTYSQFT']}
ADDRESS: {data['ADDRESS']}
STATE: {data['STATE']}
MAIN_ADDRESS: {data['MAIN_ADDRESS']}
ADMINISTRATIVE_AREA_LEVEL_2: {data['ADMINISTRATIVE_AREA_LEVEL_2']}
LOCALITY: {data['LOCALITY']}
SUBLOCALITY: {data['SUBLOCALITY']}
STREET_NAME: {data['STREET_NAME']}
LONG_NAME: {data['LONG_NAME']}
FORMATTED_ADDRESS: {data['FORMATTED_ADDRESS']}
LATITUDE: {data['LATITUDE']}
LONGITUDE: {data['LONGITUDE']}
"""
def create_text_and_embeddings():
# Write text data to 'textdata' folder and creating individual files
if write_dir.exists():
print(f"Directory exists: {write_dir}")
[f.unlink() for f in write_dir.iterdir()]
else:
print(f"Creating directory: {write_dir}")
write_dir.mkdir(exist_ok=True, parents=True)
for index, row in df.iterrows():
if "text" in row:
file_path = write_dir / f"Property_{index}.txt"
with file_path.open("w") as f:
f.write(str(row["text"]))
else:
print(f"No 'text' column found at index {index}")
print(f"Files created in {write_dir}")
Generating Embeddings and Storing in Qdrant Cloud
Once we have our text files ready, we proceed to generate embeddings. Embeddings are vector representations of our text data, capturing the semantic essence of each property. To accomplish this, we leverage Qdrant’s FastEmbed library. FastEmbed efficiently translates our property descriptions into numerical vectors, setting the stage for similarity searches in vector space.
Before diving deeper into the process, let’s introduce Qdrant Cloud. Qdrant is a robust vector database that provides a Cloud Solution, enabling users to store their generated embeddings within a Qdrant Collection. This storage is facilitated through the creation of a Qdrant Cluster, allowing for seamless management and retrieval of vector data. The Qdrant Cloud platform is designed to handle large volumes of vector embeddings, making it an ideal choice for applications requiring high-performance similarity searches.
For more detailed information about FastEmbed and its capabilities, you can visit: https://qdrant.github.io/fastembed/
You can create a free Qdrant cluster by following the instructions here: https://qdrant.tech/documentation/cloud/quickstart-cloud/
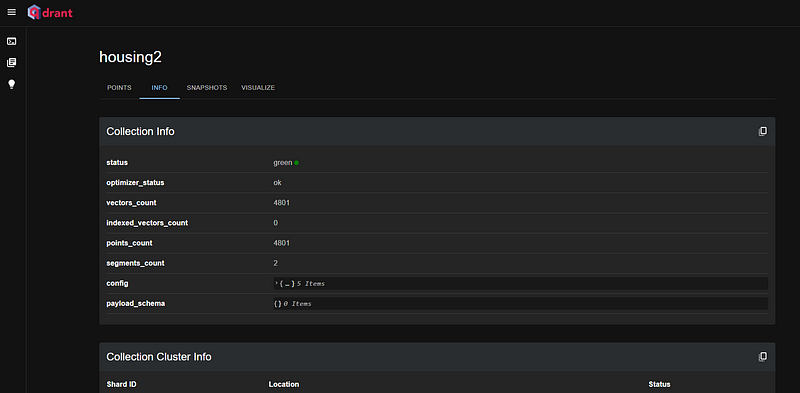
Once your Qdrant cluster is set up, you can use the code below to connect to your cluster and also configure parameters like the embedding model, and the name of the Qdrant collection that should be created to store the embeddings.
# Initialize Qdrant client
client = QdrantClient(
url="<<Enter URL>>",
api_key="<<Enter API Key",
)
# Initialize LLM and embedding model
llm = OpenAI(temperature=0.1, model="gpt-3.5-turbo")
embed_model = FastEmbedEmbedding(model_name="BAAI/bge-small-en-v1.5")
service_context = ServiceContext.from_defaults(chunk_size_limit=1024, llm=llm, embed_model=embed_model)
vector_store = QdrantVectorStore(client=client, collection_name="housing2")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
After the above configuration is complete, the creation of the Qdrant collection and the storage of embeddings is streamlined into a single efficient operation. By executing the following line of code, the ‘VectorStoreIndex.from_documents’ method not only generates embeddings for our dataset using the specified FastEmbed library but also automatically creates a new collection with the specified name within our Qdrant cluster, where these embeddings are stored:
#Create vector indexes and store in Qdrant. To be run only once in the beginning
index = VectorStoreIndex.from_documents(documents, vector_store=vector_store, service_context=service_context, storage_context=storage_context)
If you have already created your embeddings and stored them in your Qdrant collection, you can load them by using the following code:
# Load the vector index from Qdrant collection
index = VectorStoreIndex.from_vector_store(
vector_store, storage_context=storage_context
)
Two Pronged Approach
With our embeddings stored in Qdrant, we can now implement our search functionality. We have two approaches: simple and advanced.
- Simple Approach: Vector Similarity Search with Qdrant
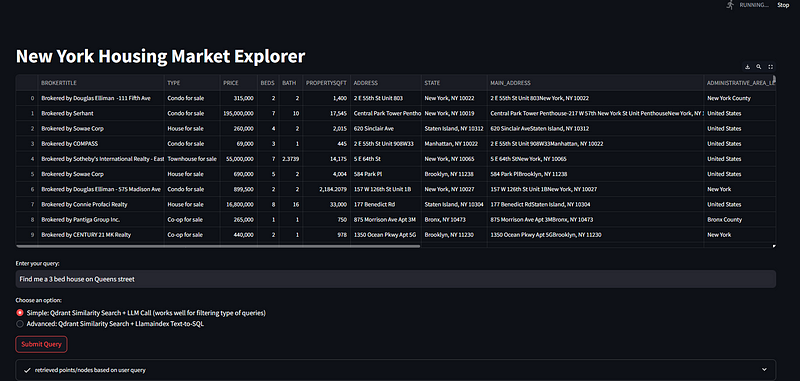
In the simple approach, when a user enters a query, we perform a vector similarity search using Qdrant’s client.search function to retrieve the top 10 most relevant properties. These results and the user query are passed to OpenAI’s GPT-3.5, which synthesizes a comprehensive response. This method is particularly effective for queries like “Suggest me some houses on Queen’s Street” or “Suggest 3 houses in Manhattan brokered by compass”.
if selection == 'Simple: Qdrant Similarity Search + LLM Call (works well for filtering type of queries)':
# Part 1, semantic search + LLM call
# Generate query vector
query_vector = embed_model.get_query_embedding(user_query)
# Perform search with Qdrant
response = client.search(collection_name="housing2", query_vector=query_vector, limit=10)
# Processing and displaying the results
text = ''
properties_list = [] # List to store multiple property dictionaries
for scored_point in response:
# Access the payload, then parse the '_node_content' JSON string to get the 'text'
node_content = json.loads(scored_point.payload['_node_content'])
text += f"\n{node_content['text']}\n"
# Initialize a new dictionary for the current property
property_dict = {}
for line in node_content['text'].split('\n'):
if line.strip(): # Ensure line is not empty
key, value = line.split(': ', 1)
property_dict[key.strip()] = value.strip()
# Add the current property dictionary to the list
properties_list.append(property_dict)
# properties_list contains all the retrieved property dictionaries
with st.status("Retrieving points/nodes based on user query", expanded = True) as status:
for property_dict in properties_list:
st.json(json.dumps(property_dict, indent=4))
print(property_dict)
status.update(label="retrieved points/nodes based on user query", state="complete", expanded=False)
with st.status("Simple Method: Generating response based on Similarity Search + LLM Call", expanded = True) as status:
prompt_template = f"""
Using the below context information respond to the user query.
context: '{properties_list}'
query: '{user_query}'
Response structure should look like this:
*Detailed Response*
*Relevant Details in Table Format*
Also, generate the latitude and longitude for all the properties included in the response in JSON object format. For example, if there are properties at 40.761255, -73.974483 and 40.7844489, -73.9807532, the JSON object should look like this limited with 3 backticks. JUST OUTPUT THE JSON, NO NEED TO INCLUDE ANY TITLE OR TEXT BEFORE IT:
```[
{{
"latitude": 40.761255,
"longitude": -73.974483
}},
{{
"latitude": 40.7844489,
"longitude": -73.9807532
}}
]
""" llm_response = llm.complete(prompt_template) response_parts = llm_response.text.split('```') st.markdown(response_parts[0])
The app displays the points/nodes matched by the vector similarity search in a Streamlit status box:

Below the vector similarity search results, we display the final output received from OpenAI’s GPT 3.5:

2\. **Advanced Approach: Combining Qdrant Vector Search with LlamaIndex Text-to-SQL**
The advanced approach integrates vector similarity search with LlamaIndex’s Text-to-SQL capabilities, offering a robust solution for queries that demand intricate insights, such as:
* ‘Find the cheapest 3 houses with 3 beds’
* ‘Give me a list of the 3 houses with an area greater than 2000 sqft in the locality of New York County’
* ‘Find me the 3 cheapest houses with more than 3 baths’
Depending on the nature of the query, the SQLAutoVectorQueryEngine intelligently decides whether to employ vector similarity search, the Text-to-SQL engine, or a combination of both. This method ensures an optimal blend of precision and context-awareness, providing users with the most relevant and detailed information.

```python
elif selection == 'Advanced: Qdrant Similarity Search + Llamaindex Text-to-SQL':
#Part 2, Semantic Search + Text-to-SQL
with st.status("Advanced Method: Generating response based on Qdrant Similarity Search + Llamaindex Text-to-SQL", expanded = True):
df2 = df.drop('text', axis=1)
#Create a SQLite database and engine
engine = create_engine("sqlite:///NY_House_Dataset.db?mode=ro", connect_args={"uri": True})
sql_database = SQLDatabase(engine)
#Convert the DataFrame to a SQL table within the SQLite database
df2.to_sql('housing_data_sql', con=engine, if_exists='replace', index=False)
#Build sql query engine
sql_query_engine = NLSQLTableQueryEngine(
sql_database=sql_database
)
vector_store_info = VectorStoreInfo(
content_info="Housing data details for NY",
metadata_info = [
MetadataInfo(name="BROKERTITLE", type="str", description="Title of the broker"),
MetadataInfo(name="TYPE", type="str", description="Type of the house"),
MetadataInfo(name="PRICE", type="float", description="Price of the house"),
MetadataInfo(name="BEDS", type="int", description="Number of bedrooms"),
MetadataInfo(name="BATH", type="float", description="Number of bathrooms"),
MetadataInfo(name="PROPERTYSQFT", type="float", description="Square footage of the property"),
MetadataInfo(name="ADDRESS", type="str", description="Full address of the house"),
MetadataInfo(name="STATE", type="str", description="State of the house"),
MetadataInfo(name="MAIN_ADDRESS", type="str", description="Main address information"),
MetadataInfo(name="ADMINISTRATIVE_AREA_LEVEL_2", type="str", description="Administrative area level 2 information"),
MetadataInfo(name="LOCALITY", type="str", description="Locality information"),
MetadataInfo(name="SUBLOCALITY", type="str", description="Sublocality information"),
MetadataInfo(name="STREET_NAME", type="str", description="Street name"),
MetadataInfo(name="LONG_NAME", type="str", description="Long name of the house"),
MetadataInfo(name="FORMATTED_ADDRESS", type="str", description="Formatted address"),
MetadataInfo(name="LATITUDE", type="float", description="Latitude coordinate of the house"),
MetadataInfo(name="LONGITUDE", type="float", description="Longitude coordinate of the house"),
],
)
vector_auto_retriever = VectorIndexAutoRetriever(
index, vector_store_info=vector_store_info
)
retriever_query_engine = RetrieverQueryEngine.from_args(
vector_auto_retriever, service_context=service_context
)
sql_tool = QueryEngineTool.from_defaults(
query_engine=sql_query_engine,
description=(
"Useful for translating a natural language query into a SQL query over"
" a table 'houses', containing prices of New York houses, providing valuable insights into the real estate market in the region. It includes information such as broker titles, house types, prices, number of bedrooms and bathrooms, property square footage, addresses, state, administrative and local areas, street names, and geographical coordinates."
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=retriever_query_engine,
description=(
f"Useful for answering questions about different housing listings in New York. Use this to refine your answers"
),
)
query_engine = SQLAutoVectorQueryEngine(
sql_tool, vector_tool, service_context=service_context
)
response = query_engine.query(f"{user_query}+. Provide a detailed response and include lONG_NAME, name of broker, number of beds, number of baths, propertysqft and FORMATTED_ADDRESS. ALWAYS USE LIKE in WHERE CLAUSE. ALWAYS RESPOND IN WELL FORMATTED MARKDOWN")
st.markdown(response.response)
Showcasing Results with a UI
Using Streamlit, we build an interactive interface that not only displays the search results but also allows users to explore property details in depth. The UI allows users to provide their text input and also choose between the two approaches (simple and advanced) by means of a radio button. Once the user submits the query, the output is generated based on the selected approach and presented in a well-formatted manner.
Live Demo: https://huggingface.co/spaces/AI-ANK/AI-Real-Estate-Search-Qdrant-Llamaindex
Conclusion
This AI-powered real estate search engine exemplifies how modern AI technologies can be integrated to create an intuitive and powerful search tool. From embedding generation to complex query processing, each component plays a crucial role in delivering a user-friendly and efficient property search experience.
With Qdrant and LlamaIndex at its core, the system offers an intuitive and efficient means to navigate the vast New York housing market. For those interested in exploring further, more information about Qdrant can be found at their overview documentation, and insights into the capabilities of SQLAutoVectorQueryEngine are available at LlamaIndex’s documentation. These resources provide deeper understanding and technical details for enthusiasts and developers alike.
Your insights and contributions are invaluable as I continue to evolve this tool. Feel free to delve into the project on GitHub or join me on LinkedIn for further discussions.