Building a Simple Full Stack RAG-Bot for Enterprises Using React, Qdrant, LangChain, Cohere and FastAPI


(First published on Medium)
Introduction

The journey from prototyping to production in AI-powered applications is filled with challenges, particularly when transitioning from convenient development tools like Streamlit and Gradio to more robust, scalable solutions. This transition necessitates a robust architecture capable of handling the intricacies and demands of real-world applications. My project tries to address this need, serving as a starting guide for developers to elevate their AI-driven prototypes to production-ready status.
LangChain’s powerful abstractions simplify LLM (Large Language Model) orchestration, enabling developers to easily create FastAPI endpoints for complex AI interactions. This project demonstrates how LangChain can be leveraged to build a robust and interactive application, highlighting the seamless integration with Qdrant, a scalable vector search engine.
Qdrant stands out for its user-friendly cloud services, which are crucial for managing extensive vector datasets. Its multitenancy capabilities ensure efficient resource utilization while maintaining data isolation, making it an excellent choice for enterprise applications. Qdrant’s binary quantization feature is particularly noteworthy, significantly reducing the memory footprint and accelerating search operations, thereby enhancing performance in production environments.
On the frontend, React provides a dynamic and responsive user interface, enabling real-time interactions and a smooth user experience. This combination of technologies forms the backbone of the solution, offering a scalable, efficient, and user-friendly platform for deploying AI-powered applications in a production setting.
Technology Stack Overview
The project is built upon a well-considered stack of technologies, each chosen for its strength in delivering efficient and scalable solutions for AI-powered applications.
LangChain: At the heart of the backend is LangChain, which simplifies the orchestration of LLMs. It enables the creation of intuitive FastAPI endpoints, facilitating complex AI-driven conversations and interactions.
Qdrant: Serving as the backbone for vector data management is Qdrant, a vector search engine optimized for performance and scalability. It offers cloud services that are not only user-friendly but also powerful enough to handle extensive vector datasets with ease. Two key features of Qdrant used in this project are:
Multitenancy: This feature allows for efficient use of database resources, providing isolated environments within a single Qdrant collection, which is vital for managing data securely and effectively in multi-user applications.
Binary Quantization: A method that significantly reduces the storage requirements and speeds up search operations, making it ideal for high-throughput, performance-sensitive environments.
Cohere Embeddings and LLMs: Cohere’s APIs are utilized for generating embeddings and processing natural language, offering state-of-the-art models that enhance the application’s ability to understand and respond to user queries accurately.
React: The frontend is developed using React, known for its ability to build dynamic and responsive user interfaces. React’s component-based architecture makes it possible to create interactive UIs that can efficiently update and render according to the user’s interactions, ensuring a seamless experience.
FastAPI: This modern, fast (high-performance) web framework for building APIs is known for its speed and ease of use. It’s used to create robust APIs that can handle the backend logic, including interactions with LangChain and Qdrant.
Together, these technologies create a synergistic platform that is not only powerful and efficient but also scalable and adaptable to the evolving needs of production-grade AI applications.
Key Concepts Useful in Production
As we architect solutions for production, certain features stand out for their ability to significantly impact performance and efficiency. Qdrant introduces two concepts pivotal for any AI-powered application transitioning into production: Multitenancy and Binary Quantization.
Multitenancy: Multitenancy in Qdrant allows for a single instance (collection) to serve multiple users or “tenants,” with each tenant’s data securely isolated from others. This approach optimizes resource utilization, as it negates the need for deploying separate instances for each user, thereby reducing overhead and enhancing scalability. In a production environment where resources are at a premium, and data security is paramount, multitenancy ensures that the application can scale efficiently while maintaining strict data isolation. This feature is especially beneficial for applications with a considerable number of users, each requiring personalized interactions and results based on their unique data sets.
Binary Quantization: Qdrant’s binary quantization reduces the storage requirement for vector data to just a single bit per dimension, drastically diminishing the memory footprint. This reduction enables faster search operations by leveraging efficient CPU instructions, providing a significant boost in performance — up to 40 times faster compared to using original vectors. Binary quantization is most effective for high-dimensional vectors, making it ideal for applications leveraging large language models and embeddings. The feature’s ability to balance speed and accuracy, with minimal impact on search quality when used with rescoring, makes it invaluable for high-volume, performance-critical environments.
These features provide a solid foundation for building scalable, efficient, and secure AI-powered applications ready for the demands of production environments.
Backend Infrastructure
The backend of our application is powered by FastAPI, which facilitates building robust and efficient APIs. The FastAPI framework is augmented with middleware and key components to manage CORS settings, handle file uploads, process data, and integrate with the Cohere platform for embeddings and Qdrant for vector storage.
Cross-Origin Resource Sharing (CORS)
To ensure the API is accessible from different origins, especially important in a web application, we configure CORS as follows:
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
expose_headers=["*"],
)
This setup allows requests from any origin, ensuring our frontend can communicate with the backend without cross-origin issues.
Initialization of Qdrant Cloud and Cohere Embeddings
Before diving deeper into the process, let’s introduce Qdrant Cloud. Qdrant is a robust vector database that provides a Cloud Solution, enabling users to store their generated embeddings within a Qdrant Collection. This storage is facilitated through the creation of a Qdrant Cluster, allowing for seamless management and retrieval of vector data. The Qdrant Cloud platform is designed to handle large volumes of vector embeddings, making it an ideal choice for applications requiring high-performance similarity searches.
You can create a free Qdrant cluster by following the instructions here: https://qdrant.tech/documentation/cloud/quickstart-cloud/
Once your Qdrant cluster is set up, you can use the code below to connect to your cluster and also initialize the embedding model.
embeddings = CohereEmbeddings(model="embed-english-light-v3.0")
client = QdrantClient(
url=QDRANT_URL,
api_key=QDRANT_API_KEY,
)
qdrant_client = Qdrant(client, collection_name="my_documents", embeddings)
CohereEmbeddings is initialized with a specified model to generate embeddings for the text data.
QdrantClient is configured with the URL and API key, pointing to the Qdrant service where our vectors will be stored.
qdrant_client combines the Qdrant client and Cohere embeddings, encapsulating the interaction with the Qdrant vector database.
Building the LLM Chain
One of LangChain’s powerful features is its ability to construct complex processing chains with minimal code. The get_chain function defines how requests are processed. This function orchestrates the flow from retrieving document content to generating a response based on a user’s query, utilizing LangChain abstractions for streamlined development.
def get_chain(retriever=Depends(get_retriever)):
template = "Answer the question based only on the following context:\n{context}\nQuestion: {question}"
prompt = ChatPromptTemplate.from_template(template)
model = ChatCohere(api_key=COHERE_API_KEY)
output_parser = StrOutputParser()
llm_chain = LLMChain(llm=model, prompt=prompt, output_parser=output_parser)
stuff_documents_chain = StuffDocumentsChain(llm_chain=llm_chain, document_variable_name="context")
chain = RetrievalQA(combine_documents_chain=stuff_documents_chain, retriever=retriever)
return chain
In the get_chain function, we construct a processing pipeline to generate contextual responses from user queries, utilizing LangChain’s intuitive coding model:
template: This string sets the structure for the conversation, indicating how to frame the context and the question in the dialogue. It’s a template used by the chat model to understand how to process the information.
prompt: Utilizes ChatPromptTemplate to transform the defined template into a format that can be understood and processed by the chat model. This step is crucial for guiding the model on how to handle the context and question.
model: Instantiates the chat model from Cohere with the provided API key. This model will interpret the user’s question and generate a response based on the context.
output_parser: Defines how the output from the chat model should be parsed and presented. StrOutputParser converts the model’s response into a string format for easy interpretation.
llm_chain: This is a LangChain construct that links the large language model (LLM) with the specified prompt and output parser, orchestrating the process of generating a response based on the input question and context.
stuff_documents_chain: Enhances the chain by integrating document handling, specifically managing how the context (document content) is passed to the LLM chain.
chain: Combines the document handling and LLM processing into a comprehensive RetrievalQA chain. This chain takes care of retrieving relevant document content (using the retriever) and generating an appropriate response based on the user’s question.
The ‘upload/’ Endpoint
This endpoint manages the uploading and processing of user documents:
Generates a unique group_id for session-based data isolation.
Processes and splits the uploaded document into manageable chunks.
Converts chunks into vector embeddings using Cohere’s model.
Uploads the embeddings to Qdrant, tagged with the group_id for partitioned access.
@app.post("/upload", status_code=200)
async def upload_document(response: Response, file: UploadFile = File(…)):
group_id = generate_group_id()
# response.set_cookie(key="group_id", value=group_id, httponly=True)
global document_processed
# Save the uploaded file to disk
with open(file.filename, "wb") as buffer:
shutil.copyfileobj(file.file, buffer)
loader = PyPDFLoader(file.filename)
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,
chunk_overlap=100)
all_splits = text_splitter.split_documents(data)
# Add group_id to each document's payload
for doc in all_splits:
doc.metadata['group_id'] = group_id
global qdrant_client
qdrant_client = Qdrant.from_documents(
all_splits,
embeddings,
url=QDRANT_URL,
api_key=QDRANT_API_KEY,
collection_name="my_documents",
metadata_payload_key="metadata",
quantization_config=models.BinaryQuantization(
binary=models.BinaryQuantizationConfig(always_ram=True, ), ),
)
document_processed = True
return {"filename": file.filename, "group_id": group_id}
The ‘rag/’ Endpoint
The rag/ endpoint is where the application processes user queries to generate contextual responses:
Validates the presence of a group_id.
Uses the get_retriever to fetch relevant data from Qdrant based on the user’s session.
Constructs a response chain to generate an answer from the provided context and question.
Returns the response from the LLM
@app.post("/rag", response_model=ChatResponse)
async def rag_endpoint(question: Question, group_id: str):
if group_id is None:
raise HTTPException(status_code=403,
detail="Please upload a document first.")
retriever = get_retriever(group_id)
chain = get_chain(retriever)
# Print the retrieved context
retrieved_docs = chain.retriever.get_relevant_documents(question.__root__)
print("Retrieved Documents:")
for doc in retrieved_docs:
print(doc.page_content)
result = chain.invoke(question.__root__)
return {"response": result['result']}
These endpoints, upload/ and rag/ enable us to manage document uploads, process them into searchable embeddings, and utilize these embeddings to retrieve and generate responses based on user queries. Through LangChain’s streamlined coding approach, complex data flows are managed efficiently, demonstrating the potential of combining powerful tools like Cohere and Qdrant in a production-ready application.
Frontend Mechanics
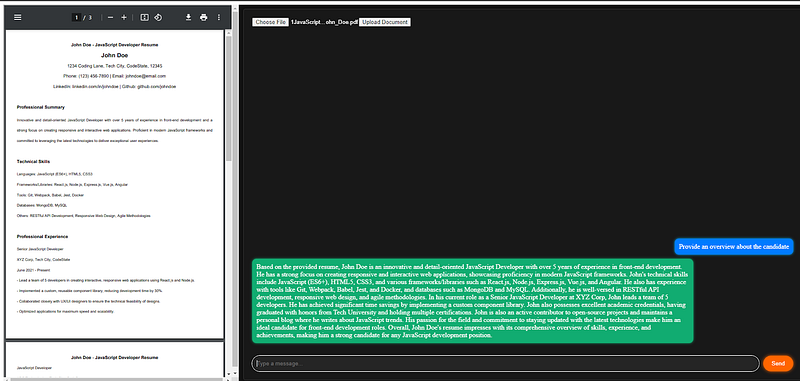
The React frontend of the application provides a dynamic and interactive user interface that facilitates seamless communication between the user and the AI-powered document chat system. The frontend consists of several components, each serving a specific purpose in the user interaction flow:
- The Document Upload Area: It allows users to choose the file they want to chat with and then allows them to upload it to the application. The document is then processed and stored in Qdrant via the backend. It’s the starting point for the document-based interaction.

- PDF Preview: Once a document is uploaded, its preview is displayed in this section on the left, allowing users to reference the content they are querying against.
- Chat Area: The core interactive element where users can type their questions related to the uploaded document. This area displays the conversation history, showing both user queries and AI-generated responses.
The send button triggers the processing of the user’s query, interacting with the backend to retrieve relevant answers from the document and displays it back to the user.

Key Functionalities
Document Upload Functionality
Users select and upload their PDF document, triggering the uploadDocument function. The function handles the file upload process, including sending the file to the backend, setting the group ID for session management, and updating the UI with the PDF preview.
This is also where error handling is implemented to notify users if there’s an issue with the server or the upload process.
const uploadDocument = async () => {
if (!file) return;
setIsLoading(true); // Start loading
const formData = new FormData();
formData.append("file", file);
try {
const response = await fetch(`${API_ENDPOINT}/upload`, { method: "POST", body: formData });
if (!response.ok) throw new Error(`HTTP error! status: ${response.status}`);
const result = await response.json();
setGroupId(result.group_id);
setPdfUrl(URL.createObjectURL(file)); // Create a URL for the uploaded file
setConversation([]);
} catch (error) {
console.error("Error uploading document:", error);
}
setIsLoading(false); // Stop loading
};
Query Processing and Response Generation (RAG)
When users send a query, the sendMessage function captures the input, sends it to the backend (/rag endpoint), and processes the returned answer.
This function is essential for facilitating the interactive chat experience, where users can get contextual answers based on their uploaded documents.
const sendMessage = async () => {
if (message.trim() === "") return;
setIsLoading(true); // Start loading
try {
const response = await fetch(`${API_ENDPOINT}/rag?group_id=${groupId}`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ __root__: message }),
});
if (!response.ok) throw new Error(`HTTP error! status: ${response.status}`);
const data = await response.json();
const outputText = data.response || "No response text found";
setConversation([…conversation, { text: outputText, from: "bot" }, { text: message, from: "user" }]);
setMessage("");
} catch (error) {
console.error("Error sending message:", error);
} finally {
setIsLoading(false); // Stop loading
}
};
Additional UI Interactions
Error Handling: The frontend is equipped with mechanisms to display error messages, enhancing robustness and user trust.
Spinner for Loading: Provides feedback during asynchronous operations like uploading or fetching data, improving the overall user experience.
In summary, the frontend mechanics focus on providing a user-friendly and efficient interface for interacting with the AI-powered document analysis system. By integrating features like live PDF preview, interactive chat, and responsive feedback mechanisms, the application delivers a cohesive and engaging user experience.
End-to-End Example
Let’s walk through an end-to-end example to illustrate the full flow of this RAG chatbot. This prototype, designed as a starting point for full-stack applications, supports PDF documents and can answer queries related to the document content. It’s particularly useful for business scenarios like interacting with company earnings call transcripts, or analyzing resumes.
Example Use Case: NVIDIA Earnings Call Transcript
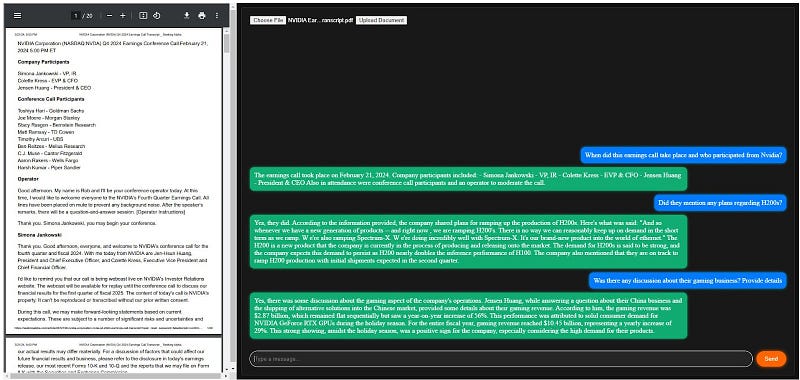
Let us walk through a simple use case of chatting with NVIDIA earnings call transcript:
- Navigate to the app’s interface, click ‘Choose File’, select the NVIDIA Earnings Call transcript, and then click ‘Upload Document’. The document will appear in the left-side PDF preview panel.
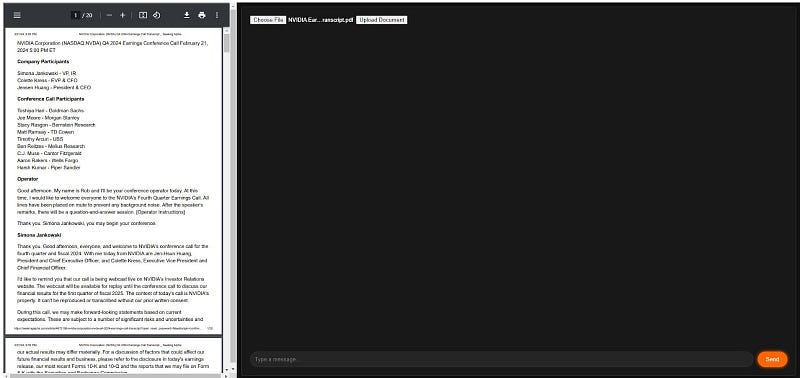
- The upload also triggers the ‘upload/’ endpoint on the server, which then generates a unique ‘group_id’ for this chat session. The server processes the PDF into text chunks, converts these into vector embeddings using Cohere, and stores them in Qdrant cloud with the associated group_id. This unique group_id ensures that the current session user is only able to access and query data they have uploaded.
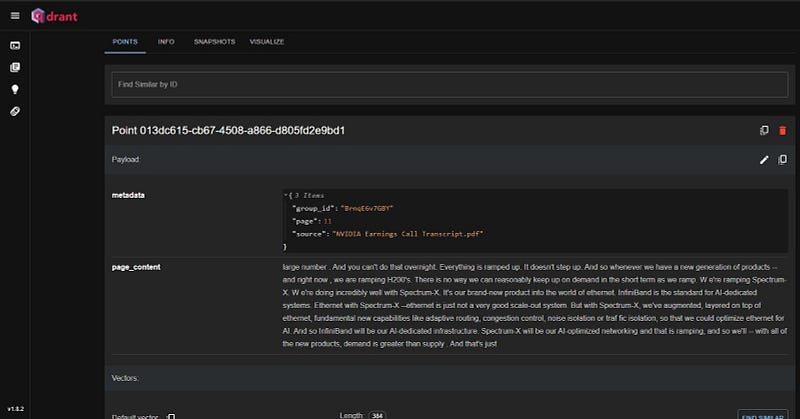
The PDF is 21 pages long and has a lot of text. Now, let’s pose some questions to our chatbot:
When did this earnings call take place and who participated from NVIDIA?
Did they mention any plans regarding H200s?
Was there any discussion about their gaming business? Provide details.
The system, leveraging LangChain, Qdrant, and Cohere, adeptly navigates the document to provide concise answers.
- While this chat session is active in one browser, let us try logging in from another browser to see how Qdrant’s multitenancy functionality works.
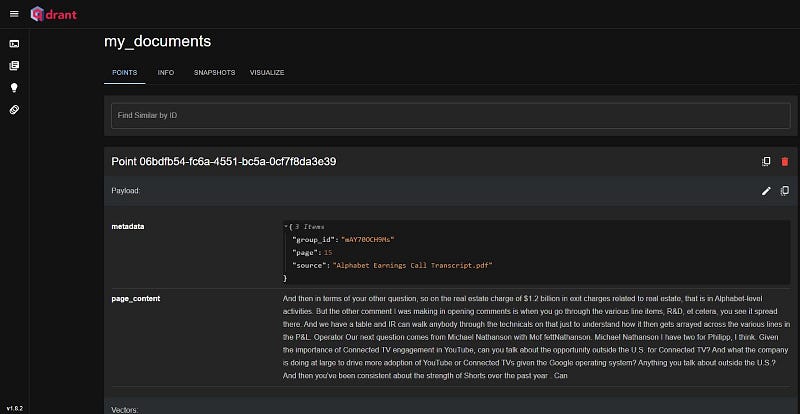
Demonstrating Multitenancy with a Separate Session
- Let’s upload Alphabet’s Earnings Call Transcript in another browser session to witness Qdrant’s multitenancy in action. Notice the different group_id generated, ensuring session-specific data isolation.
- Querying this session about ‘NVIDIA’ confirms the isolation — the system correctly states no relevant data found in Alphabet’s transcript.
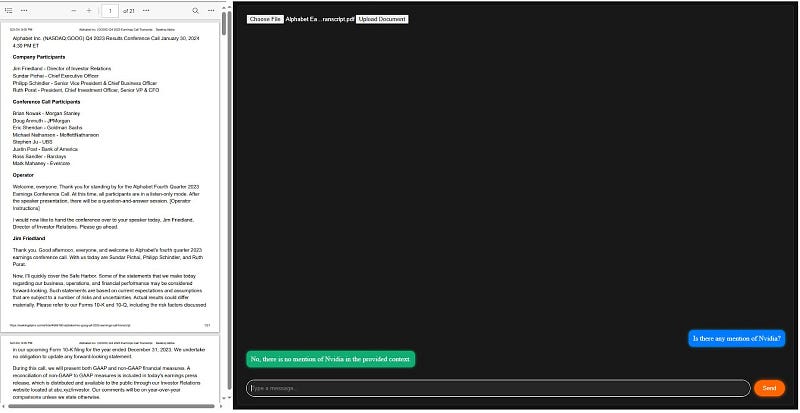
This basic demonstration highlights the system’s ability to segregate user sessions effectively. By integrating user authentication, you can further enhance data isolation, tailoring the experience to individual users and their documents. This prototype serves as a foundation, which can be expanded to include more sophisticated features and cater to various enterprise-level requirements.
Conclusion
In conclusion, this project represents a starting point for bridging the gap between AI-powered prototype development and production-ready applications. By leveraging the robust backend infrastructure powered by LangChain and Qdrant, alongside a dynamic React frontend, we’ve crafted a solution that not only demonstrates the power of AI in document understanding but also showcases how modern web technologies can be integrated to build scalable, efficient, and user-friendly applications. This prototype serves as a blueprint for developers looking to transition their AI-driven projects from concept to production, embodying the principles of scalability, efficiency, and user engagement.
Your insights and contributions are invaluable as I continue to evolve this tool. Feel free to delve into the project on GitHub or join me on LinkedIn for further discussions.